Project Overview
ALY is a tool designed to match farm producers with consumers in order to reduce food waste and increase the efficiency of the food supply chain. This project was designed at the Carlson's Analytics for Good Hackathon. As a team we recieved the Most Engaged and Inquisitive Award. My role in this hackathon was to disambiguate data, feature engineer two datasets, design a database schema, develop a pipeline to train a machine learning model, and connect the backend to the frontend.

Our team planning the project on a whiteboard at the hackathon.
Background
For this hackathon our team was provided data regarding the operations of The Good Acre. This data was a collection of orders and contracts provided to local farmers and to what extent they were fulfilled. Our goal was to use this data to better predict the completion rate of orders and contracts. This would allow us to better match producers with consumers and reduce food waste. The data we recieved was quite messy and split across two datasets. My goal, using pandas, was to standardize, clean, and combine these datasets into a single dataset that could be stored on a database available to the frontend.

Data after being cleaned and combined as shown on our web-application.
Development
For this project the team and I decided to use three different metrics to measure success of a farmer and contract relationship. These metrics were: On Time & In Full, On Time, and Fullfilment Average. In our situation, On Time & In Full meant that the farmer delivered the exact amount of produce on the exact date requested. On Time meant that the farmer delivered the produce on the exact date requested but it may not be sufficient. Fullfilment average was the percent that a farmer was able to deliver the requested produce even if it was not on the requested date. Our dashboard was capable of showcasing these metrics.
While getting these metrics was not difficult, pairing contracts with farmer produce was as they were not guarenteed to be on the same date. We settled on a greedy algorithm that would pair the closest contract to a farmer's produce. This was not ideal, but without knowing which produce aligned with which contract, this was the only option we had.
Metrics used to measure success on our dashboard.
Machine Learning Model
Once the data was entered on our database, I developed three different machine learning models to help predict the success of a farmer and contract relationship. These models were a Stochastic Gradient Descent Classifier, Multivariate Regression Model, and a Random Forest Classifier. For both the Stochastic Gradient Descent Classifier and the Multivariate Regression Model the results were not optimal as the size of our data was far too small only spanning two years. The Ensamble Random Forest Classifier however, was able to achieve an accuracy of over 80% on our test data. This model was pickled, hosted on a FastAPI server, and pipelined into our frontend.
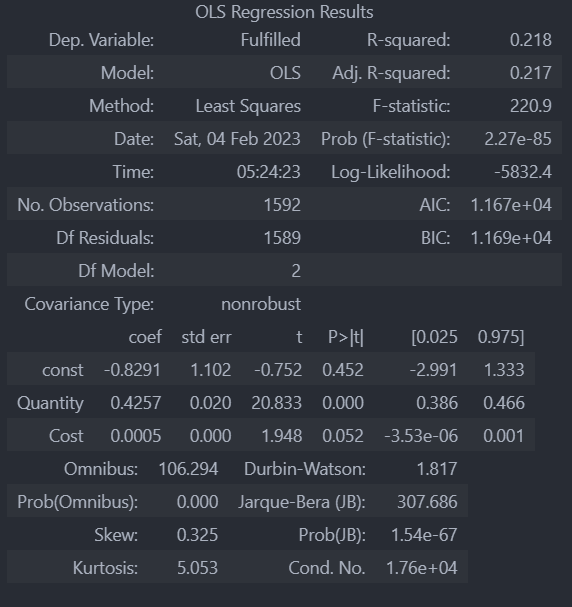
Values of our Multivariable Linear Regression Model when optimizing.
Outcome
Overall, this project was incredibly insightful as to how analytics can be used to solve real world problems. I learned quite a lot about my team and I'm happy that our efforts were recognized. Shown below is the final product of our hackathon.
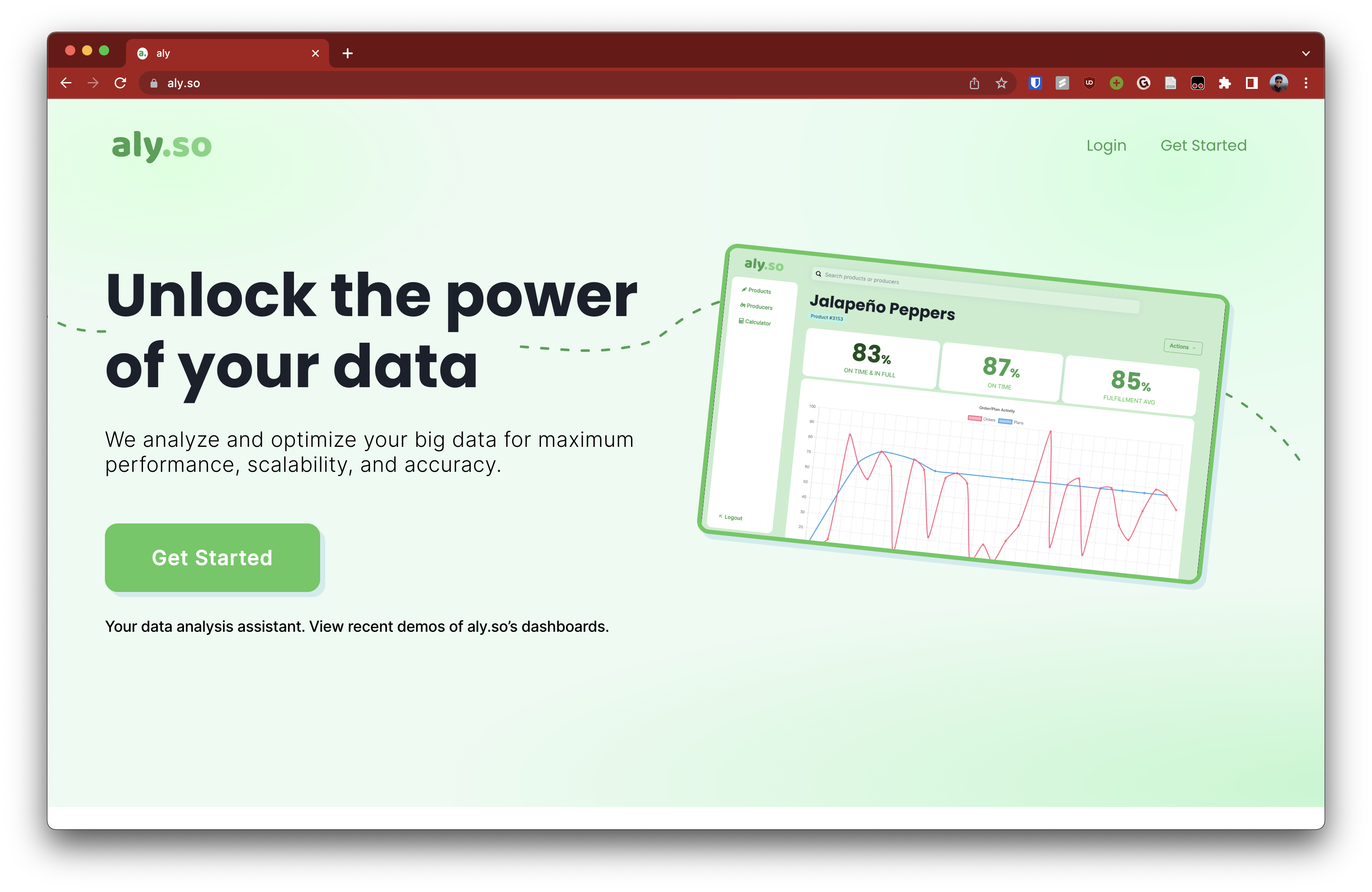
Our final product at the hackathon.